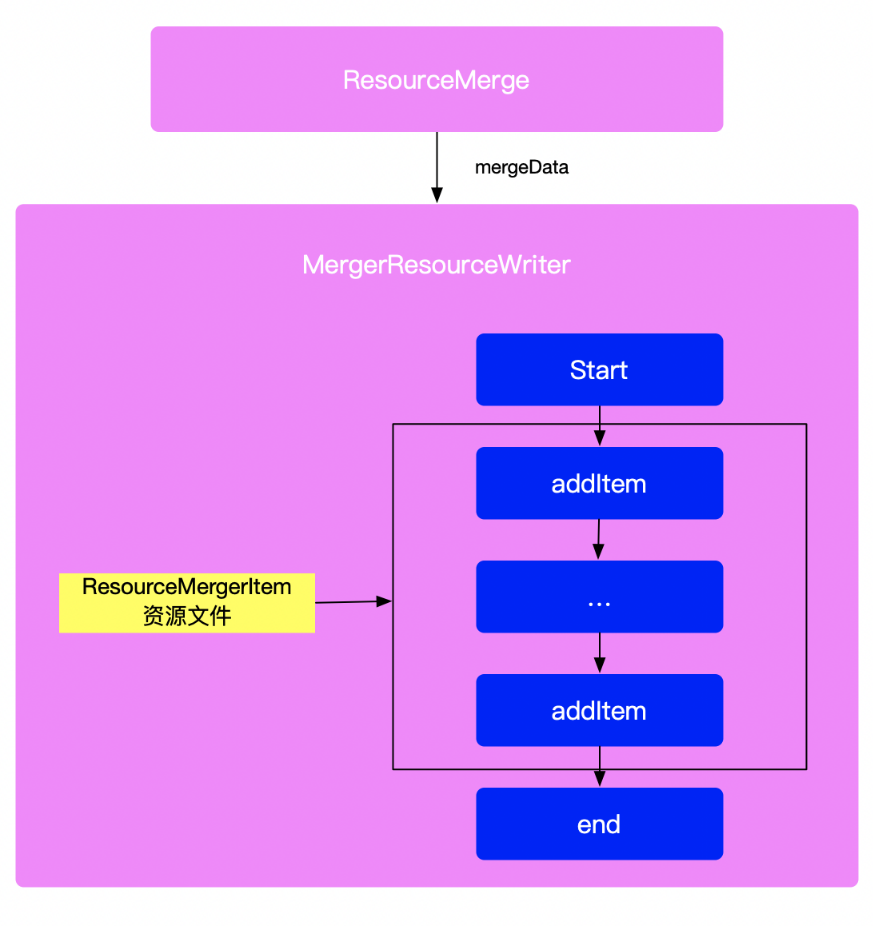
// create a new merger and populate it with the sets. //2.创建一个ResourceMerger,后面会把resourceSets对其进行填充 ResourceMerger merger = new ResourceMerger(getMinSdk().get()); ... //3 创建WorkerExecutorFacade、ResourceCompilatonService try (WorkerExecutorFacade workerExecutorFacade = getAaptWorkerFacade(); ResourceCompilationService resourceCompiler = getResourceProcessor( this, flags, processResources, getAapt2())) { ...
publicvoidmergeData(@NonNull MergeConsumer<I> consumer, boolean doCleanUp) throws MergingException { consumer.start(mFactory);//xian try { // get all the items keys. Set<String> dataItemKeys = new HashSet<>(); //遍历获取所有资源的key for (S dataSet : mDataSets) {//mDataSets就是之前 // quick check on duplicates in the resource set. dataSet.checkItems(); ListMultimap<String, I> map = dataSet.getDataMap(); dataItemKeys.addAll(map.keySet()); }
// loop on all the data items. for (String dataItemKey : dataItemKeys) { //如果是styleable资源的话进行styleable的merge if (requiresMerge(dataItemKey)) { // get all the available items, from the lower priority, to the higher // priority List<I> items = new ArrayList<>(mDataSets.size()); for (S dataSet : mDataSets) {
// look for the resource key in the set ListMultimap<String, I> itemMap = dataSet.getDataMap();
try { // get all the items keys. Set<String> dataItemKeys = new HashSet<>();
for (S dataSet : mDataSets) { // quick check on duplicates in the resource set. dataSet.checkItems(); ListMultimap<String, I> map = dataSet.getDataMap(); dataItemKeys.addAll(map.keySet()); }
// loop on all the data items. for (String dataItemKey : dataItemKeys) { ...
// for each items, look in the data sets, starting from the end of the list. I previouslyWritten = null; I toWrite = null;
boolean foundIgnoredItem = false;
setLoop: for (int i = mDataSets.size() - 1 ; i >= 0 ; i--) { S dataSet = mDataSets.get(i);
// look for the resource key in the set ListMultimap<String, I> itemMap = dataSet.getDataMap();
if (!itemMap.containsKey(dataItemKey)) { continue; } List<I> items = itemMap.get(dataItemKey); if (items.isEmpty()) { continue; }
for (int ii = items.size() - 1 ; ii >= 0 ; ii--) { I item = items.get(ii);
if (consumer.ignoreItemInMerge(item)) { foundIgnoredItem = true; continue; }
} elseif (previouslyWritten == null || previouslyWritten == toWrite) { // easy one: new or updated res consumer.addItem(toWrite);// } else { // replacement of a resource by another.
// force write the new value toWrite.setTouched(); consumer.addItem(toWrite); // and remove the old one consumer.removeItem(previouslyWritten, toWrite); } } } finally { consumer.end();//添加资源后走consumer.end()方法 }
@Override publicvoidaddItem(@NonNullfinal ResourceMergerItem item)throws ConsumerException { final ResourceFile.FileType type = item.getSourceType();
if (type == ResourceFile.FileType.XML_VALUES) { mValuesResMap.put(item.getQualifiers(), item); } else { checkState(item.getSourceFile() != null); // This is a single value file or a set of generated files. Only write it if the state // is TOUCHED. if (item.isTouched()) { File file = item.getFile(); String folderName = getFolderName(item);
// If we are going to shrink resources, the resource shrinker needs to have the // final merged uncompiled file. if (mergeWriterRequest.getNotCompiledOutputDirectory() != null) { File typeDir = new File( mergeWriterRequest.getNotCompiledOutputDirectory(), folderName); FileUtils.mkdirs(typeDir); FileUtils.copyFileToDirectory(outFile, typeDir); }
override fun close(){ if (requests.isEmpty()) { return } val maxWorkersCount = aapt2Input.maxWorkerCount.get()
// First remove all JVM res compiler compatible files to be consumed by the kotlin compiler. //1.移除掉requests中所有供Koltin编译器和JVM资源编译器兼容的文件 val jvmRequests = requests.filter { canCompileResourceInJvm(it.inputFile, it.isPngCrunching) } requests.removeAll(jvmRequests)
// Split all requests into buckets, giving each worker the same number of files to process var ord = 0 val jvmBuckets = jvmRequests.groupByTo(HashMap(maxWorkersCount)) { (ord++) % maxWorkersCount } //2. 供Koltin编译器和JVM资源编译器兼容的文件交给ResourceCompilerRunnable处理 jvmBuckets.values.forEach { bucket -> workerExecutor.noIsolation() .submit(ResourceCompilerRunnable::class.java) { it.initializeWith(projectPath = projectPath, taskOwner = taskOwner, analyticsService = analyticsService) it.request.set(bucket) } }
funcanCompileResourceInJvm(file: File, requirePngCrunching: Boolean): Boolean { // Hidden files, while skipped, are still supported. if (file.isHidden) returntrue
val pathData = extractPathData(file) if (pathData.resourceDirectory == VALUES_DIRECTORY_PREFIX && pathData.extension == XML_EXTENSION) {//values目录下的xml文件返回true // file is a values table. returntrue } else { val type = ResourceType.fromFolderName(pathData.resourceDirectory) ?: returnfalse if (type != ResourceType.RAW) { if (pathData.extension == XML_EXTENSION) {//res目录下的的xml文件 returntrue } elseif (pathData.extension.endsWith(PNG_EXTENSION)) {// // If we don't need to perform patch9 processing or png crunching we can process. return pathData.extension != PATCH_9_EXTENSION && !requirePngCrunching } } } returntrue }
// TODO: find a way to re-use the blame logger between requests val blameLogger = blameLoggerFor(request, LoggerWrapper.getLogger(this::class.java)) compileResource(request.inputFile, request.outputDirectory, options, blameLogger) } }
//... // Extract resource type information from the full path. val pathData = extractPathData(file, options.sourcePath ?: file.absolutePath) // Determine how to compile the file based on its type. val compileFunction = getCompileMethod(pathData, logger) //... } privatefungetCompileMethod(pathData: ResourcePathData, logger: BlameLogger): (ResourcePathData, File, ResourceCompilerOptions, BlameLogger) -> Unit { if (pathData.resourceDirectory == VALUES_DIRECTORY_PREFIX && pathData.extension == XML_EXTENSION) { pathData.extension = RESOURCE_TABLE_EXTENSION return ::compileTable } else { val type = ResourceType.fromFolderName(pathData.resourceDirectory) if (type == null) { val errorMsg = "Invalid resource type '${pathData.resourceDirectory}'" + " for file ${pathData.file.absolutePath}" logger?.warning(errorMsg) error(errorMsg) } if (type != ResourceType.RAW) { if (pathData.extension == XML_EXTENSION) { return ::compileXml } elseif (pathData.extension.endsWith(PNG_EXTENSION)) { return ::compilePng } } } return ::compileFile }
@Throws(TimeoutException::class, Aapt2InternalException::class, Aapt2Exception::class) overridefundoCompile(request: CompileResourceRequest, logger: ILogger) { val waitForTask = WaitForTaskCompletion(displayName, logger) try { processOutput.delegate = waitForTask //写入编译命令 Aapt2DaemonUtil.requestCompile(writer, request) // Temporary workaround for b/111629686, manually generate the partial R file for raw and non xml res. //... //等待进程执行编译的结果 val result = waitForTask.future.get(daemonTimeouts.compile, daemonTimeouts.compileUnit) //... } finally { processOutput.delegate = noOutputExpected } }
funmakeCompileCommand(request: CompileResourceRequest): ImmutableList<String> { val parameters = ImmutableList.Builder<String>()
if (request.isPseudoLocalize) { parameters.add("--pseudo-localize") }
if (!request.isPngCrunching) { // Only pass --no-crunch for png files and not for 9-patch files as that breaks them. val lowerName = request.inputFile.path.toLowerCase(Locale.US) if (lowerName.endsWith(SdkConstants.DOT_PNG) && !lowerName.endsWith(SdkConstants.DOT_9PNG)) { parameters.add("--no-crunch") } }
if (request.partialRFile != null) { parameters.add("--output-text-symbols", request.partialRFile!!.absolutePath) }